← All posts
News
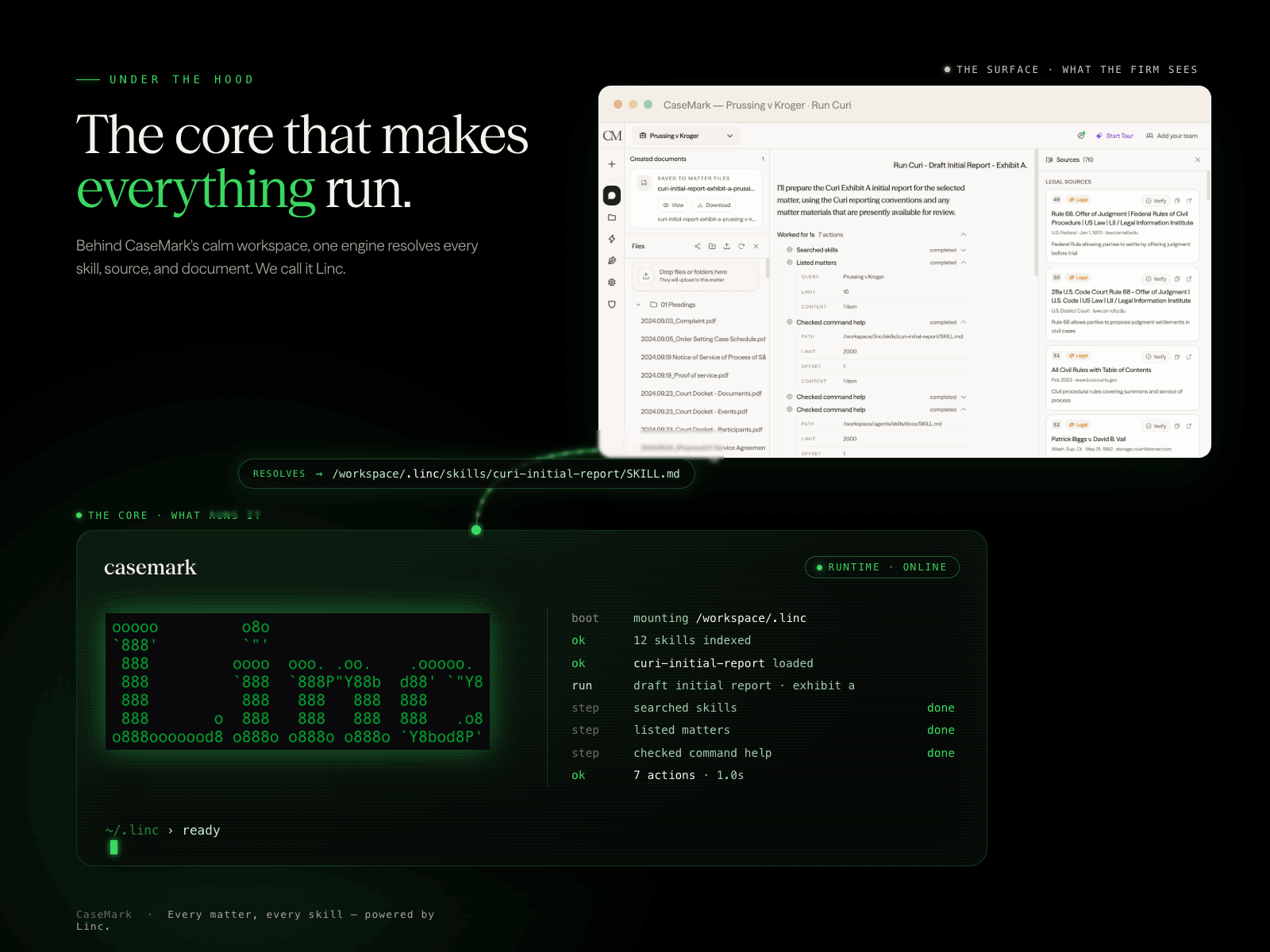
Adapting to AI: CaseMark's Perspective on OpenAI's DevDay on Legal Technology
In the wake of OpenAI DevDay, we at CaseMark are excitedly integrating GPT-4-turbo & GPTs into our legal tech solutions, aiming to leapfrog industry standards. However, our initial tests reveal both the immense potential and the current limitations of these AI advancements in handling complex legal tasks.